CSV(Comma Separated Values) 파일은 각 칼럼의 값을 쉼표로 구분하는 파일 포맷입니다.
특별한 라이브러리가 없어도 파일을 쉽게 읽고 쓸 수 있기 때문에 많이 쓰이는 형식입니다.
파이썬에는 CSV 파일을 효율적으로 읽고 쓰기 위한 csv 모듈이 존재합니다.
파이썬의 csv 모듈을 통해 CSV 파일을 다루는 방법을 알아보겠습니다.
1. CSV 파일 쓰기
CSV 파일을 생성하고 작성하기 위한 코드는 다음과 같습니다.
# -*- coding: utf-8 -*-
import csv
import datetime
fields = ['ID', 'Date in', 'Name', 'Quantity', 'Unit Price', 'Total']
sample_list = [
[1, datetime.date.today(), 'Product Name 1', 5, 10000, 50000],
[2, datetime.date.today(), 'Product Name 2', 10, 3000, 30000],
[3, datetime.date.today(), 'Product Name 3', 3, 7000, 21000]
]
sample_dict = [
{'ID': 1, 'Date in': datetime.date.today(), 'Name': 'Product Name 1', 'Quantity': 5, 'Unit Price': 10000,
'Total': 50000},
{'ID': 2, 'Date in': datetime.date.today(), 'Name': 'Product Name 2', 'Quantity': 10, 'Unit Price': 3000,
'Total': 30000},
{'ID': 3, 'Date in': datetime.date.today(), 'Name': 'Product Name 3', 'Quantity': 3, 'Unit Price': 7000,
'Total': 21000},
]
def write_to_file_from_list(filepath):
with open(filepath, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(fields)
writer.writerows(sample_list)
def write_to_file_from_dict(filepath):
with open(filepath, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fields)
writer.writeheader()
writer.writerows(sample_dict)
if __name__ == '__main__':
write_to_file_from_list('D:\\test_list.csv')
write_to_file_from_dict('D:\\test_dict.csv')
list에 있는 데이터를 사용하거나 dict 데이터를 통해 작성이 가능합니다.
먼저 list를 사용한 write_to_file_from_list()는 writerow() 혹은 writerows()를 통해 파일을 쓰고 있습니다.
단일 라인은 writerow()로 작성하면 되고 writerows()로는 여러 라인을 한 번에 작성할 수 있습니다.
그래서 writerows()를 호출할 때는 이중 리스트가 사용된 것을 알 수 있습니다.
다음으로 write_to_file_from_dict()는 DictWriter()로 생성을 하며 fieldnames가 반드시 지정돼야 합니다.
파이썬 dict 타입이 기본적으로 순서가 정해져 있지 않기 때문에 지정한 fieldnames의 순서대로 저장이 됩니다.
헤더를 추가하기 위해 writeheader()를 먼저 호출한 것을 확인할 수 있습니다.
몇 줄 안되는 코드로 간단하게 CSV 파일 생성이 가능합니다.
만약 필드 값에 쉼표가 포함되는 경우에는 자동적으로 필드 값을 ""로 감싸서 정상적으로 표시가 되도록 해줍니다.
2. CSV 파일 읽기
CSV 파일을 읽는 것 역시 간단합니다.
# -*- coding: utf-8 -*-
import csv
def read_from_file_to_list(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
for cell in row:
print('{:>15}'.format(cell), end='')
print()
def read_from_file_to_dict(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
fields = reader.fieldnames
for field in fields:
print('{:>15}'.format(field), end='')
print()
for row in reader:
for field in fields:
print('{:>15}'.format(row[field]), end='')
print()
if __name__ == '__main__':
read_from_file_to_list('D:\\test_list.csv')
print()
read_from_file_to_dict('D:\\test_list.csv')
쓰기와 동일하게 reader() 혹은 DicReader()를 사용해서 각 필드를 읽을 수 있습니다.
reader()로 생성된 객체를 for 문으로 읽어오면 각 줄(row)을 읽어올 수 있습니다.
다시 row를 반복문으로 읽어오면 각 필드(cell)를 얻을 수 있습니다.
간단하게 2개의 중첩된 for 문으로 모든 필드를 가져올 수 있습니다.
DictReader()의 경우 fieldnames를 통해 헤더를 순서대로 읽어올 수 있습니다.
먼저 읽어온 헤더를 순서대로 출력해주고 그 이후에는 reader()와 동일하게 for 문으로 각 줄(row)을 읽어 옵니다.
다만 reader()와 다르게 각 row에는 dict 타입이 저장되어 있습니다.
그래서 fieldnames에서 가져온 필드 순서대로 [] 연산자를 통해 접근하면 순차적으로 가져올 수 있습니다.

두 함수 모두 동일한 결과를 출력합니다.
3. CSV Dialect 설정
기본적으로 CSV는 쉼표(,)를 사용해서 각 필드를 구분하도록 되어 있습니다.
다만 엑셀에서 생성한 탭으로 각 필드를 구분하는 파일을 읽어야 하는 경우도 있습니다.
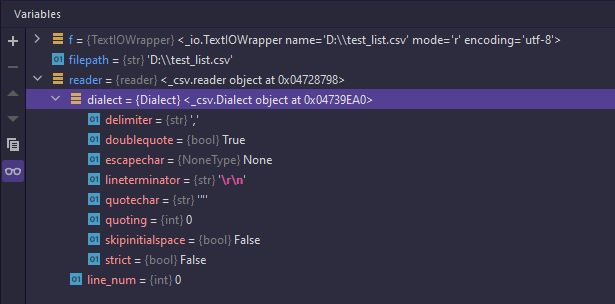
다음과 같이 생성된 csv 객체에는 dialect라는 변수가 있는 것을 확인할 수 있습니다.
원하는 형태의 구분자나 개행 문자를 설정하려면 아래와 같은 코드를 작성하면 됩니다.
csv.register_dialect('custom_dialect', delimiter='\t', lineterminator='\n', quotechar='*',
quoting=csv.QUOTE_ALL)
writer = csv.writer(f, 'custom_dialect')구분자를 쉼표 대신 탭으로 변경하고 개행 문자 역시 '\n'을 사용하도록 했습니다.
quoting은 csv.QUOTE_ALL로 설정했기 때문에 모든 필드가 quotechar에 설정한 문자로 감싸 집니다.
CSV의 dialect에 설정할 수 있는 값은 다음과 같습니다.
|
delimiter |
각 필드를 구분하기 위한 문자 (기본값: ',') |
|
doublequote |
필드에 delimiter 등의 특수 문자가 있을 때, True일 때 quotechar로 필드 전체를 감싸고 False일 때 escapechar로 해당 문자에만 적용(False일 때는 escapechar가 반드시 설정되어야 함) (기본값: True) |
|
escapechar |
doublequote가 False이고 quoting이 csv.QUOTE_NONE일 때 escapechar로 특수문자 처리 (기본값: None) |
|
lineterminator |
개행 문자 설정 (기본값: '\r\n') |
|
quotechar |
특수 문자 포함 시 해당 필드를 감쌀 문자 (기본값: '"') |
|
quoting |
특수 문자가 포함된 필드를 감쌀 때 처리 방법 설정 (기본값: csv.QUOTE_MINIMAL) |
|
skipinitialspace |
True일 때 구분자 다음의 공백 문자를 무시 (기본값: False) |
|
strict |
잘못된 CSV 입력일 때 csv.Error 예외 발생 (기본값: False) |
대부분은 설정된 기본값을 사용하면 CSV를 읽고 쓸 수 있습니다.
엑셀 파일이나 유닉스 시스템을 위한 csv.excel, csv.excel_tab, csv.unix_dialect가 미리 정의되어 있습니다.
마지막으로 해당 파일의 내용을 기반으로 dialect를 추측하는 Sniffer 클래스가 존재합니다.
with open(filepath, 'r', encoding='utf-8') as f:
dialect = csv.Sniffer().sniff(f.read(1024))
reader = csv.reader(f, dialect)
다만 되도록이면 읽고 쓸 때 명확하게 dialect를 지정하는 것을 추천합니다.
이것으로 Python을 통해 CSV 파일을 읽고 쓸 수 있습니다.
'Programming > Python' 카테고리의 다른 글
| [Python] 파이썬 튜플(tuple) 사용 방법 (0) | 2021.04.09 |
|---|---|
| [Python] 파이썬 리스트(list) 사용 방법 (5) | 2021.04.08 |
| 파이썬 openpyxl로 엑셀(Excel) 파일 읽기/쓰기 (0) | 2020.07.25 |
| 파이썬에서 JSON 데이터 형식 처리 (0) | 2019.10.24 |
| 파이썬 정규표현식으로 쉼표(콤마, Comma)가 있는 숫자 찾기 (0) | 2018.09.14 |